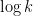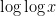Kevin Ford, Ben Green, Sergei Konyagin, James Maynard, and I have just uploaded to the arXiv our paper “Long gaps between primes“. This is a followup work to our two previous papers (discussed in this previous post), in which we had simultaneously shown that the maximal gap
![\displaystyle G(X) := \sup_{p_n, p_{n+1} \leq X} p_{n+1}-p_n]()
between primes up to ![{X}]() exhibited a lower bound of the shape
exhibited a lower bound of the shape
![\displaystyle G(X) \geq f(X) \log X \frac{\log \log X \log\log\log\log X}{(\log\log\log X)^2} \ \ \ \ \ (1)]()
for some function ![{f(X)}]() that went to infinity as
that went to infinity as ![{X \rightarrow \infty}]() ; this improved upon previous work of Rankin and other authors, who established the same bound but with
; this improved upon previous work of Rankin and other authors, who established the same bound but with ![{f(X)}]() replaced by a constant. (Again, see the previous post for a more detailed discussion.)
replaced by a constant. (Again, see the previous post for a more detailed discussion.)
In our previous papers, we did not specify a particular growth rate for ![{f(X)}]() . In my paper with Kevin, Ben, and Sergei, there was a good reason for this: our argument relied (amongst other things) on the inverse conjecture on the Gowers norms, as well as the Siegel-Walfisz theorem, and the known proofs of both results both have ineffective constants, rendering our growth function
. In my paper with Kevin, Ben, and Sergei, there was a good reason for this: our argument relied (amongst other things) on the inverse conjecture on the Gowers norms, as well as the Siegel-Walfisz theorem, and the known proofs of both results both have ineffective constants, rendering our growth function ![{f(X)}]() similarly ineffective. Maynard’s approach ostensibly also relies on the Siegel-Walfisz theorem, but (as shown in another recent paper of his) can be made quite effective, even when tracking
similarly ineffective. Maynard’s approach ostensibly also relies on the Siegel-Walfisz theorem, but (as shown in another recent paper of his) can be made quite effective, even when tracking ![{k}]() -tuples of fairly large size (about
-tuples of fairly large size (about ![{\log^c x}]() for some small
for some small ![{c}]() ). If one carefully makes all the bounds in Maynard’s argument quantitative, one eventually ends up with a growth rate
). If one carefully makes all the bounds in Maynard’s argument quantitative, one eventually ends up with a growth rate ![{f(X)}]() of shape
of shape
![\displaystyle f(X) \asymp \frac{\log \log \log X}{\log\log\log\log X}, \ \ \ \ \ (2)]()
thus leading to a bound
![\displaystyle G(X) \gg \log X \frac{\log \log X}{\log\log\log X}]()
on the gaps between primes for large ![{X}]() ; this is an unpublished calculation of James’.
; this is an unpublished calculation of James’.
In this paper we make a further refinement of this calculation to obtain a growth rate
![\displaystyle f(X) \asymp \log \log \log X \ \ \ \ \ (3)]()
leading to a bound of the form
![\displaystyle G(X) \geq c \log X \frac{\log \log X \log\log\log\log X}{\log\log\log X} \ \ \ \ \ (4)]()
for large ![{X}]() and some small constant
and some small constant ![{c}]() . Furthermore, this appears to be the limit of current technology (in particular, falling short of Cramer’s conjecture that
. Furthermore, this appears to be the limit of current technology (in particular, falling short of Cramer’s conjecture that ![{G(X)}]() is comparable to
is comparable to ![{\log^2 X}]() ); in the spirit of Erdös’ original prize on this problem, I would like to offer 10,000 USD for anyone who can show (in a refereed publication, of course) that the constant
); in the spirit of Erdös’ original prize on this problem, I would like to offer 10,000 USD for anyone who can show (in a refereed publication, of course) that the constant ![{c}]() here can be replaced by an arbitrarily large constant
here can be replaced by an arbitrarily large constant ![{C}]() .
.
The reason for the growth rate (3) is as follows. After following the sieving process discussed in the previous post, the problem comes down to something like the following: can one sieve out all (or almost all) of the primes in ![{[x,y]}]() by removing one residue class modulo
by removing one residue class modulo ![{p}]() for all primes
for all primes ![{p}]() in (say)
in (say) ![{[x/4,x/2]}]() ? Very roughly speaking, if one can solve this problem with
? Very roughly speaking, if one can solve this problem with ![{y = g(x) x}]() , then one can obtain a growth rate on
, then one can obtain a growth rate on ![{f(X)}]() of the shape
of the shape ![{f(X) \sim g(\log X)}]() . (This is an oversimplification, as one actually has to sieve out a random subset of the primes, rather than all the primes in
. (This is an oversimplification, as one actually has to sieve out a random subset of the primes, rather than all the primes in ![{[x,y]}]() , but never mind this detail for now.)
, but never mind this detail for now.)
Using the quantitative “dense clusters of primes” machinery of Maynard, one can find lots of ![{k}]() -tuples in
-tuples in ![{[x,y]}]() which contain at least
which contain at least ![{\gg \log k}]() primes, for
primes, for ![{k}]() as large as
as large as ![{\log^c x}]() or so (so that
or so (so that ![{\log k}]() is about
is about ![{\log\log x}]() ). By considering
). By considering ![{k}]() -tuples in arithmetic progression, this means that one can find lots of residue classes modulo a given prime
-tuples in arithmetic progression, this means that one can find lots of residue classes modulo a given prime ![{p}]() in
in ![{[x/4,x/2]}]() that capture about
that capture about ![{\log\log x}]() primes. In principle, this means that union of all these residue classes can cover about
primes. In principle, this means that union of all these residue classes can cover about ![{\frac{x}{\log x} \log\log x}]() primes, allowing one to take
primes, allowing one to take ![{g(x)}]() as large as
as large as ![{\log\log x}]() , which corresponds to (3). However, there is a catch: the residue classes for different primes
, which corresponds to (3). However, there is a catch: the residue classes for different primes ![{p}]() may collide with each other, reducing the efficiency of the covering. In our previous papers on the subject, we selected the residue classes randomly, which meant that we had to insert an additional logarithmic safety margin in expected number of times each prime would be shifted out by one of the residue classes, in order to guarantee that we would (with high probability) sift out most of the primes. This additional safety margin is ultimately responsible for the
may collide with each other, reducing the efficiency of the covering. In our previous papers on the subject, we selected the residue classes randomly, which meant that we had to insert an additional logarithmic safety margin in expected number of times each prime would be shifted out by one of the residue classes, in order to guarantee that we would (with high probability) sift out most of the primes. This additional safety margin is ultimately responsible for the ![{\log\log\log\log X}]() loss in (2).
loss in (2).
The main innovation of this paper, beyond detailing James’ unpublished calculations, is to use ideas from the literature on efficient hypergraph covering, to avoid the need for a logarithmic safety margin. The hypergraph covering problem, roughly speaking, is to try to cover a set of ![{n}]() vertices using as few “edges” from a given hypergraph
vertices using as few “edges” from a given hypergraph ![{H}]() as possible. If each edge has
as possible. If each edge has ![{m}]() vertices, then one certainly needs at least
vertices, then one certainly needs at least ![{n/m}]() edges to cover all the vertices, and the question is to see if one can come close to attaining this bound given some reasonable uniform distribution hypotheses on the hypergraph
edges to cover all the vertices, and the question is to see if one can come close to attaining this bound given some reasonable uniform distribution hypotheses on the hypergraph ![{H}]() . As before, random methods tend to require something like
. As before, random methods tend to require something like ![{\frac{n}{m} \log r}]() edges before one expects to cover, say
edges before one expects to cover, say ![{1-1/r}]() of the vertices.
of the vertices.
However, it turns out (under reasonable hypotheses on ![{H}]() ) to eliminate this logarithmic loss, by using what is now known as the “semi-random method” or the “Rödl nibble”. The idea is to randomly select a small number of edges (a first “nibble”) – small enough that the edges are unlikely to overlap much with each other, thus obtaining maximal efficiency. Then, one pauses to remove all the edges from
) to eliminate this logarithmic loss, by using what is now known as the “semi-random method” or the “Rödl nibble”. The idea is to randomly select a small number of edges (a first “nibble”) – small enough that the edges are unlikely to overlap much with each other, thus obtaining maximal efficiency. Then, one pauses to remove all the edges from ![{H}]() that intersect edges from this first nibble, so that all remaining edges will not overlap with the existing edges. One then randomly selects another small number of edges (a second “nibble”), and repeats this process until enough nibbles are taken to cover most of the vertices. Remarkably, it turns out that under some reasonable assumptions on the hypergraph
that intersect edges from this first nibble, so that all remaining edges will not overlap with the existing edges. One then randomly selects another small number of edges (a second “nibble”), and repeats this process until enough nibbles are taken to cover most of the vertices. Remarkably, it turns out that under some reasonable assumptions on the hypergraph ![{H}]() , one can maintain control on the uniform distribution of the edges throughout the nibbling process, and obtain an efficient hypergraph covering. This strategy was carried out in detail in an influential paper of Pippenger and Spencer.
, one can maintain control on the uniform distribution of the edges throughout the nibbling process, and obtain an efficient hypergraph covering. This strategy was carried out in detail in an influential paper of Pippenger and Spencer.
In our setup, the vertices are the primes in ![{[x,y]}]() , and the edges are the intersection of the primes with various residue classes. (Technically, we have to work with a family of hypergraphs indexed by a prime
, and the edges are the intersection of the primes with various residue classes. (Technically, we have to work with a family of hypergraphs indexed by a prime ![{p}]() , rather than a single hypergraph, but let me ignore this minor technical detail.) The semi-random method would in principle eliminate the logarithmic loss and recover the bound (3). However, there is a catch: the analysis of Pippenger and Spencer relies heavily on the assumption that the hypergraph is uniform, that is to say all edges have the same size. In our context, this requirement would mean that each residue class captures exactly the same number of primes, which is not the case; we only control the number of primes in an average sense, but we were unable to obtain any concentration of measure to come close to verifying this hypothesis. And indeed, the semi-random method, when applied naively, does not work well with edges of variable size – the problem is that edges of large size are much more likely to be eliminated after each nibble than edges of small size, since they have many more vertices that could overlap with the previous nibbles. Since the large edges are clearly the more useful ones for the covering problem than small ones, this bias towards eliminating large edges significantly reduces the efficiency of the semi-random method (and also greatly complicates the analysis of that method).
, rather than a single hypergraph, but let me ignore this minor technical detail.) The semi-random method would in principle eliminate the logarithmic loss and recover the bound (3). However, there is a catch: the analysis of Pippenger and Spencer relies heavily on the assumption that the hypergraph is uniform, that is to say all edges have the same size. In our context, this requirement would mean that each residue class captures exactly the same number of primes, which is not the case; we only control the number of primes in an average sense, but we were unable to obtain any concentration of measure to come close to verifying this hypothesis. And indeed, the semi-random method, when applied naively, does not work well with edges of variable size – the problem is that edges of large size are much more likely to be eliminated after each nibble than edges of small size, since they have many more vertices that could overlap with the previous nibbles. Since the large edges are clearly the more useful ones for the covering problem than small ones, this bias towards eliminating large edges significantly reduces the efficiency of the semi-random method (and also greatly complicates the analysis of that method).
Our solution to this is to iteratively reweight the probability distribution on edges after each nibble to compensate for this bias effect, giving larger edges a greater weight than smaller edges. It turns out that there is a natural way to do this reweighting that allows one to repeat the Pippenger-Spencer analysis in the presence of edges of variable size, and this ultimately allows us to recover the full growth rate (3).
To go beyond (3), one either has to find a lot of residue classes that can capture significantly more than ![{\log\log x}]() primes of size
primes of size ![{x}]() (which is the limit of the multidimensional Selberg sieve of Maynard and myself), or else one has to find a very different method to produce large gaps between primes than the Erdös-Rankin method, which is the method used in all previous work on the subject.
(which is the limit of the multidimensional Selberg sieve of Maynard and myself), or else one has to find a very different method to produce large gaps between primes than the Erdös-Rankin method, which is the method used in all previous work on the subject.
It turns out that the arguments in this paper can be combined with the Maier matrix method to also produce chains of consecutive large prime gaps whose size is of the order of (4); three of us (Kevin, James, and myself) will detail this in a future paper. (A similar combination was also recently observed in connection with our earlier result (1) by Pintz, but there are some additional technical wrinkles required to recover the full gain of (3) for the chains of large gaps problem.)




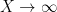







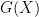


![{[x,y]}](http://s0.wp.com/latex.php?latex=%7B%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[x/4,x/2]}](http://s0.wp.com/latex.php?latex=%7B%5Bx%2F4%2Cx%2F2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)