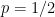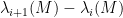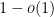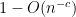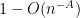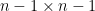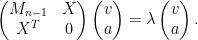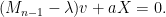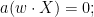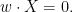Van Vu and I have just uploaded to the arXiv our paper “Random matrices have simple spectrum“. Recall that an ![{n \times n}]() Hermitian matrix is said to have simple eigenvalues if all of its
Hermitian matrix is said to have simple eigenvalues if all of its ![{n}]() eigenvalues are distinct. This is a very typical property of matrices to have: for instance, as discussed in this previous post, in the space of all
eigenvalues are distinct. This is a very typical property of matrices to have: for instance, as discussed in this previous post, in the space of all ![{n \times n}]() Hermitian matrices, the space of matrices without all eigenvalues simple has codimension three, and for real symmetric cases this space has codimension two. In particular, given any random matrix ensemble of Hermitian or real symmetric matrices with an absolutely continuous distribution, we conclude that random matrices drawn from this ensemble will almost surely have simple eigenvalues.
Hermitian matrices, the space of matrices without all eigenvalues simple has codimension three, and for real symmetric cases this space has codimension two. In particular, given any random matrix ensemble of Hermitian or real symmetric matrices with an absolutely continuous distribution, we conclude that random matrices drawn from this ensemble will almost surely have simple eigenvalues.
For discrete random matrix ensembles, though, the above argument breaks down, even though general universality heuristics predict that the statistics of discrete ensembles should behave similarly to those of continuous ensembles. A model case here is the adjacency matrix ![{M_n}]() of an Erdös-Rényi graph – a graph on
of an Erdös-Rényi graph – a graph on ![{n}]() vertices in which any pair of vertices has an independent probability
vertices in which any pair of vertices has an independent probability ![{p}]() of being in the graph. For the purposes of this paper one should view
of being in the graph. For the purposes of this paper one should view ![{p}]() as fixed, e.g.
as fixed, e.g. ![{p=1/2}]() , while
, while ![{n}]() is an asymptotic parameter going to infinity. In this context, our main result is the following (answering a question of Babai):
is an asymptotic parameter going to infinity. In this context, our main result is the following (answering a question of Babai):
Theorem 1 With probability ![{1-o(1)}]() ,
, ![{M_n}]() has simple eigenvalues.
has simple eigenvalues.
Our argument works for more general Wigner-type matrix ensembles, but for sake of illustration we will stick with the Erdös-Renyi case. Previous work on local universality for such matrix models (e.g. the work of Erdos, Knowles, Yau, and Yin) was able to show that any individual eigenvalue gap ![{\lambda_{i+1}(M)-\lambda_i(M)}]() did not vanish with probability
did not vanish with probability ![{1-o(1)}]() (in fact
(in fact ![{1-O(n^{-c})}]() for some absolute constant
for some absolute constant ![{c>0}]() ), but because there are
), but because there are ![{n}]() different gaps that one has to simultaneously ensure to be non-zero, this did not give Theorem 1 as one is forced to apply the union bound.
different gaps that one has to simultaneously ensure to be non-zero, this did not give Theorem 1 as one is forced to apply the union bound.
Our argument in fact gives simplicity of the spectrum with probability ![{1-O(n^{-A})}]() for any fixed
for any fixed ![{A}]() ; in a subsequent paper we also show that it gives a quantitative lower bound on the eigenvalue gaps (analogous to how many results on the singularity probability of random matrices can be upgraded to a bound on the least singular value).
; in a subsequent paper we also show that it gives a quantitative lower bound on the eigenvalue gaps (analogous to how many results on the singularity probability of random matrices can be upgraded to a bound on the least singular value).
The basic idea of argument can be sketched as follows. Suppose that ![{M_n}]() has a repeated eigenvalue
has a repeated eigenvalue ![{\lambda}]() . We split
. We split
![\displaystyle M_n = \begin{pmatrix} M_{n-1} & X \\ X^T & 0 \end{pmatrix}]()
for a random ![{n-1 \times n-1}]() minor
minor ![{M_{n-1}}]() and a random sign vector
and a random sign vector ![{X}]() ; crucially,
; crucially, ![{X}]() and
and ![{M_{n-1}}]() are independent. If
are independent. If ![{M_n}]() has a repeated eigenvalue
has a repeated eigenvalue ![{\lambda}]() , then by the Cauchy interlacing law,
, then by the Cauchy interlacing law, ![{M_{n-1}}]() also has an eigenvalue
also has an eigenvalue ![{\lambda}]() . We now write down the eigenvector equation for
. We now write down the eigenvector equation for ![{M_n}]() at
at ![{\lambda}]() :
:
![\displaystyle \begin{pmatrix} M_{n-1} & X \\ X^T & 0 \end{pmatrix} \begin{pmatrix} v \\ a \end{pmatrix} = \lambda \begin{pmatrix} v \\ a \end{pmatrix}.]()
Extracting the top ![{n-1}]() coefficients, we obtain
coefficients, we obtain
![\displaystyle (M_{n-1} - \lambda) v + a X = 0.]()
If we let ![{w}]() be the
be the ![{\lambda}]() -eigenvector of
-eigenvector of ![{M_{n-1}}]() , then by taking inner products with
, then by taking inner products with ![{w}]() we conclude that
we conclude that
![\displaystyle a (w \cdot X) = 0;]()
we typically expect ![{a}]() to be non-zero, in which case we arrive at
to be non-zero, in which case we arrive at
![\displaystyle w \cdot X = 0.]()
In other words, in order for ![{M_n}]() to have a repeated eigenvalue, the top right column
to have a repeated eigenvalue, the top right column ![{X}]() of
of ![{M_n}]() has to be orthogonal to an eigenvector
has to be orthogonal to an eigenvector ![{w}]() of the minor
of the minor ![{M_{n-1}}]() . Note that
. Note that ![{X}]() and
and ![{w}]() are going to be independent (once we specify which eigenvector of
are going to be independent (once we specify which eigenvector of ![{M_{n-1}}]() to take as
to take as ![{w}]() ). On the other hand, thanks to inverse Littlewood-Offord theory (specifically, we use an inverse Littlewood-Offord theorem of Nguyen and Vu), we know that the vector
). On the other hand, thanks to inverse Littlewood-Offord theory (specifically, we use an inverse Littlewood-Offord theorem of Nguyen and Vu), we know that the vector ![{X}]() is unlikely to be orthogonal to any given vector
is unlikely to be orthogonal to any given vector ![{w}]() independent of
independent of ![{X}]() , unless the coefficients of
, unless the coefficients of ![{w}]() are extremely special (specifically, that most of them lie in a generalised arithmetic progression). The main remaining difficulty is then to show that eigenvectors of a random matrix are typically not of this special form, and this relies on a conditioning argument originally used by Komlós to bound the singularity probability of a random sign matrix. (Basically, if an eigenvector has this special form, then one can use a fraction of the rows and columns of the random matrix to determine the eigenvector completely, while still preserving enough randomness in the remaining portion of the matrix so that this vector will in fact not be an eigenvector with high probability.)
are extremely special (specifically, that most of them lie in a generalised arithmetic progression). The main remaining difficulty is then to show that eigenvectors of a random matrix are typically not of this special form, and this relies on a conditioning argument originally used by Komlós to bound the singularity probability of a random sign matrix. (Basically, if an eigenvector has this special form, then one can use a fraction of the rows and columns of the random matrix to determine the eigenvector completely, while still preserving enough randomness in the remaining portion of the matrix so that this vector will in fact not be an eigenvector with high probability.)